What: OCR & R; Analyze standardized hardcopy forms electronically
Why: Win a card game with a lot of cards to remember (car quartett)
How
You need:
- The card game
- A scanner
- Gimp
- A linux machine
- An hour free time
1. Setup a virtual machine or an existing linux
I used Ubuntu Xenial64bit. Maybe, you have to adapt the steps a little bit.
- Install tesseract
-
1
sudo apt-get update
-
1
sudo apt-get install -y tesseract-ocr tesseract-ocr-deu
-
- Install Java
-
1
sudo apt-get install -y openjdk-8-jdk
-
2. Scan the cards
Scan all the cards. Make one image per card. Make sure, you placed the cards all the time at the same position in the scanner (for example upper right corner). All images should have the same resolution and size. Thus, the same regions on the image should correspond to the same region in all the cards (for example a name field). The cards can look like this (you can guess what game I played ;-)):
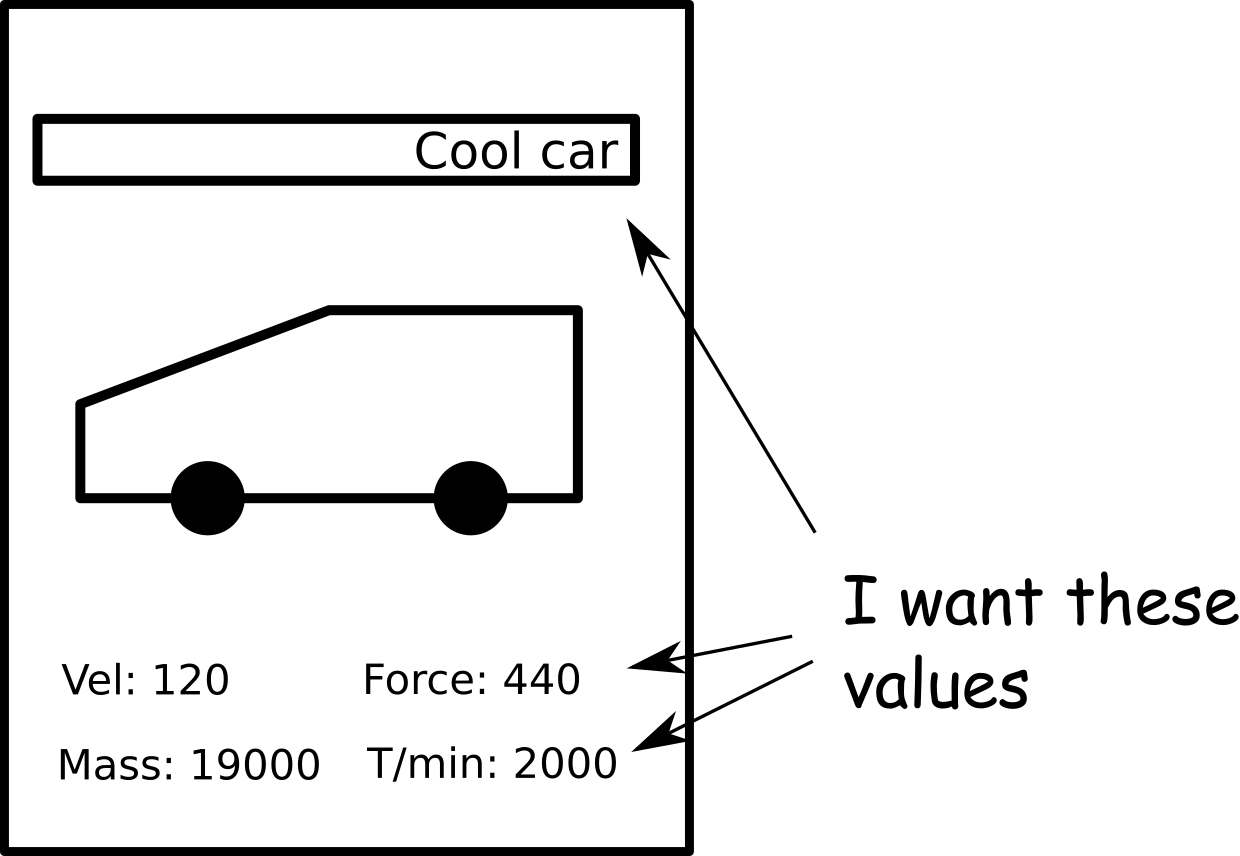
You have to tweak the images a little bit to get good OCR results. Here is what I did:
- Use Gimp to blur the images (Filter ⇒ Blur ⇒ Blur)
3. Basic image processing with Java & tesseract
The cards I scanned had some defined regions with numerical or text values (see figure above). You can enhance the OCR results dramatically, if you know ehere to look for the text. Create a small class containing the information about each region. This class should also contain a flag if you look for text or numerical values.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | public class ImageInfo { public final String name; public final boolean number; public final int leftUpX; public final int leftUpY; public final int rightDownX; public final int rightDownY; public ImageInfo(String name, boolean number, int leftUpX, int leftUpY, int rightDownX, int rightDownY) { this.name = name; this.number = number; this.leftUpX = leftUpX; this.leftUpY = leftUpY; this.rightDownX = rightDownX; this.rightDownY = rightDownY; } } |
Set up the regions for your image as you like. Thats what I used for the cards (coordinates are pixels in the scanned image).
1 2 3 4 5 6 7 8 9 | final static List infos = Arrays.asList(new ImageInfo[] { new ImageInfo("Name", false, 160, 158, 460, 40), new ImageInfo("Geschwindigkeit", true, 200, 685, 70, 35), new ImageInfo("Hubraum", true, 460, 685, 110, 40), new ImageInfo("Gewicht", true, 180, 790, 110, 40), new ImageInfo("Zylinder", true, 475, 790, 60, 40), new ImageInfo("Leistung", true, 200, 895, 70, 40), new ImageInfo("Umdrehung", true, 470, 895, 90, 40) }); |
Now, process each image. For each image I did the following steps:
- Read in the image
1
BufferedImage image= ImageIO.read(imageFile);
- Transformed image to black/white ⇒ Better OCR results
1 2 3 4 5 6 7 8 9 10 11 12 13 14
int width = image.getWidth(); int height = image.getHeight(); for (int y = 0; y < height; y++) { for (int x = 0; x < width; x++) { int rgb = image.getRGB(x, y); int blue = rgb & 0xff; int green = (rgb & 0xff00) >> 8; int red = (rgb & 0xff0000) >> 16; if(red>210&&blue>210&&green>210){ image.setRGB(x, y, new Color(0, 0, 0).getRGB()); } else{ image.setRGB(x, y, new Color(255, 255, 255).getRGB()); } } }
- Do some basic clipping to extract one image for each region on the card you are interested in. Start tesseract for each image.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
for (ImageInfo imageInfo : infos) { File outputFile = "the output png file, should be in the same directory for the same cards"; ImageIO.write(image.getSubimage(imageInfo.leftUpX, imageInfo.leftUpY, imageInfo.rightDownX, imageInfo.rightDownY), "png", outputFile); ProcessBuilder processBuilder; // -psm 6 works best for my case of one line of text in each image. Remember: each image contain ONE numerical or text value from the card. if(imageInfo.number){ // Restrict tesseract to digits. processBuilder = new ProcessBuilder("tesseract", "-psm", "6", outputFile.toString(), path.resolve(outputFileNameBase + "_"+imageInfo.name).toString(), "digits"); } else{ processBuilder = new ProcessBuilder("tesseract", "-psm", "6", outputFile.toString(), path.resolve(outputFileNameBase + "_"+imageInfo.name).toString()); } processBuilder.start(); }
- Collect the results from the text file output of tesseract (or read directly from the output stream of the process). Maybe, there is also a batch mode of tesseract???
4. Analyze the results with R
Lets assume you have the results now in a list like this:
Geschwindigkeit;Gewicht;Hubraum;Leistung;Name;Umdrehung;Zylinder 120;19.000;12.800;440;Volvo FH12-440;2.200;6 ...
You can read in the values easily in R with:
1 2 | # The 5th row contains the names of the cars in my example. This is used as dimension.
cards=read.csv("share/result.csv", sep=";", header=T, row.names=5) |
This is read in as a data frame. You can get a first impression of the best values with the summary function:
1 | summary(cards) |
Write a simple function to get the values for all categories:
1 2 3 | bestCandidates=function(attribute){
subset(cards, cards[attribute]==max(cards[attribute], na.rm=T))
} |
And apply it:
1 2 | dimensions=names(cards) lapply(dimensions, bestCandidates) |
And voila: You have to remember just a few cards with the highest values. Next time I ask for „Zylinder“ in case Ihave the „Scania R620“.
1 2 3 | [[6]]
Geschwindigkeit Gewicht Hubraum Leistung Umdrehung Zylinder
Scania R620 125 26 15.6 620 1.9 8 |